


Kerasにおけるtrain、validation、testについて簡単に説明します。
目次
各データをざっくり言うと
- train
- 実際にニューラルネットワークの重みを更新する学習データ。
- validation
- ニューラルネットワークのハイパーパラメータの良し悪しを確かめるための検証データ。学習は行わない。
- test
- 学習後に汎化性能を確かめるテストデータ。学習は行わない。
テストデータは汎化性能をチェックするために、最後に(理想的には一度だけ)利用します。
ハイパーパラメータとは?
- 各層のニューロン数、バッチサイズ、パラメータ更新の際の学習係数など、人の手によって設定されるパラメータのこと。
- ニューラルネットワークの重みは、学習アルゴリズムによって自動獲得されるものであり、ハイパーパラメータではない。
- 一般的に、ハイパーパラメータをいろいろな値で試しながら、うまく学習できるケースを探すという作業が必要になる。
Kerasでの確認
サマリー
以下のように、model.fitのvalidation_split=に「0.1」を渡した場合、学習データ(train)のうち、10%が検証データ(validation)として使用されることになります。
model.fit(Xtrain, Ytrain, batch_size=BATCH_SIZE, epochs=NUM_EPOCHS,
validation_split=0.1)
model.summary()での出力は、以下のようになります。
- 60000データのうち、90%である54000が学習データ(train)に使用される。
- 60000データのうち、10%である6000が検証データ(validation)に使用される。
Train on 54000 samples, validate on 6000 samples
同様に、model.fitのvalidation_split=に「0.2」を渡した場合、学習データ(train)のうち、20%が検証データ(validation)として使用されることになります。
model.fit(Xtrain, Ytrain, batch_size=BATCH_SIZE, epochs=NUM_EPOCHS,
validation_split=0.2)
model.summary()での出力は、以下のようになります。
- 60000データのうち、80%である48000が学習データ(train)に使用される。
- 60000データのうち、20%である12000が検証データ(validation)に使用される。
Train on 48000 samples, validate on 12000 samples
実行ログ
model.fit()のログで出力される値では以下の通り。
- acc:学習データ(train)の精度
- val_acc:検証データ(validation)の精度
48000/48000 [==============================] - 1s 27us/step - loss: 0.0596 - acc: 0.9798 - val_loss: 0.0818 - val_acc: 0.9778
acc < val_acc の場合
学習データの精度が検証データの精度より低い場合、学習が不十分であると言えます。
エポック数を増やしてみましょう。
学習データの精度は評価データの精度を超えるべきです。そうでないときは、十分に学習していないことになります。その場合は学習回数を大幅に増やしてみましょう。
過学習?
検証データ(validation)の精度推移は、過学習かどうかの確認にも用いられます。
以下のようなソースでグラフ表示を行います。
# 学習実行
history = model.fit(Xtrain, Ytrain, batch_size=BATCH_SIZE, epochs=NUM_EPOCHS,
validation_split=0.2)
# グラフ描画
# Accuracy
plt.plot(range(1, NUM_EPOCHS+1), history.history['acc'], "-o")
plt.plot(range(1, NUM_EPOCHS+1), history.history['val_acc'], "-o")
plt.title('model accuracy')
plt.ylabel('accuracy') # Y軸ラベル
plt.xlabel('epoch') # X軸ラベル
plt.grid()
plt.legend(['acc', 'val_acc'], loc='best')
plt.show()
下のグラフのような結果であるとします。
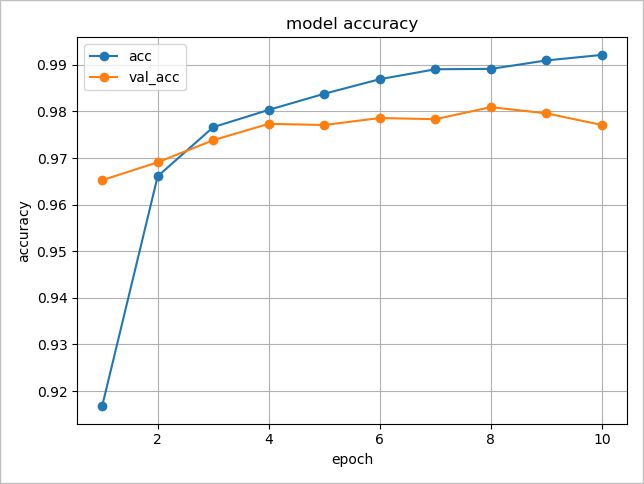
8エポック以降、検証データ(validation)の精度が下がってきており、過学習が疑われます。
参考
Keras Document:ModelクラスAPI
https://keras.io/ja/models/model/



