PyCharmでKerasのチュートリアル
PyCharmでKerasのチュートリアルとして、Sequentialモデルを実行する方法をご紹介します。
目次
条件
- PyCharm
- Python 3.6.7
プロジェクトの作成
PCにPython、PyCharm、Kerasなどがインストール済みであるものとします。
各種ソフトのインストールについては、以下の記事をご確認ください。
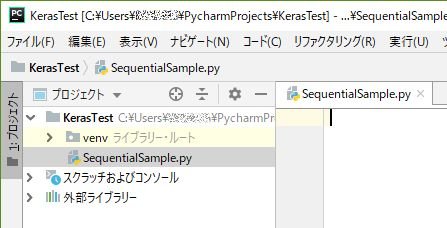
Pythonファイル作成
作成したプロジェクトをPyCharmで開きます。
(プロジェクト名はKerasTestとしています。)
プロジェクトを右クリック選択して、新規 > Pythonファイルを選択します。
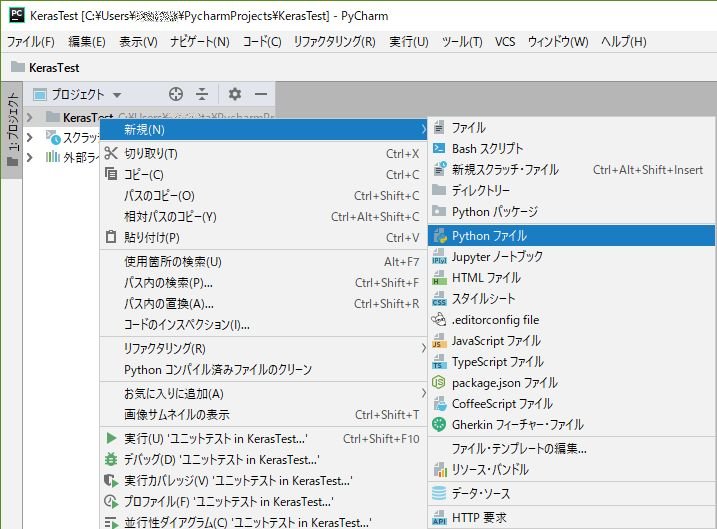
新規Pythonファイルダイアログが表示されるので、任意の名前(ここではSequentialSample)を入力してOKボタンを押します。
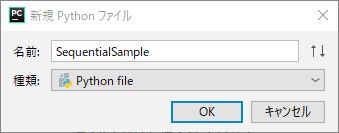
プロジェクトの下に指定した名前のPythonファイルが作成されます。
とりあえず実行
Kerasの公式ドキュメントに記載されている例を作成したPythonファイルにコピーアンドペーストします。

# MLPを用いた二値分類
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Dropout
# 疑似データの生成
x_train = np.random.random((1000, 20))
y_train = np.random.randint(2, size=(1000, 1))
x_test = np.random.random((100, 20))
y_test = np.random.randint(2, size=(100, 1))
model = Sequential()
model.add(Dense(64, input_dim=20, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model.fit(x_train, y_train,
epochs=20,
batch_size=128)
score = model.evaluate(x_test, y_test, batch_size=128)
プログラム実行
PyCharm右上の「構成の追加」をクリックします。
![]()
実行/デバッグ構成画面が開きます。
左上の+ボタンを押して「新規構成の追加」メニューを展開して「Python」を選択します。
名前に任意の値(ここでは「Keras実行」)を入力し、スクリプト・パスで先ほど作成したPythonファイルを選択します。
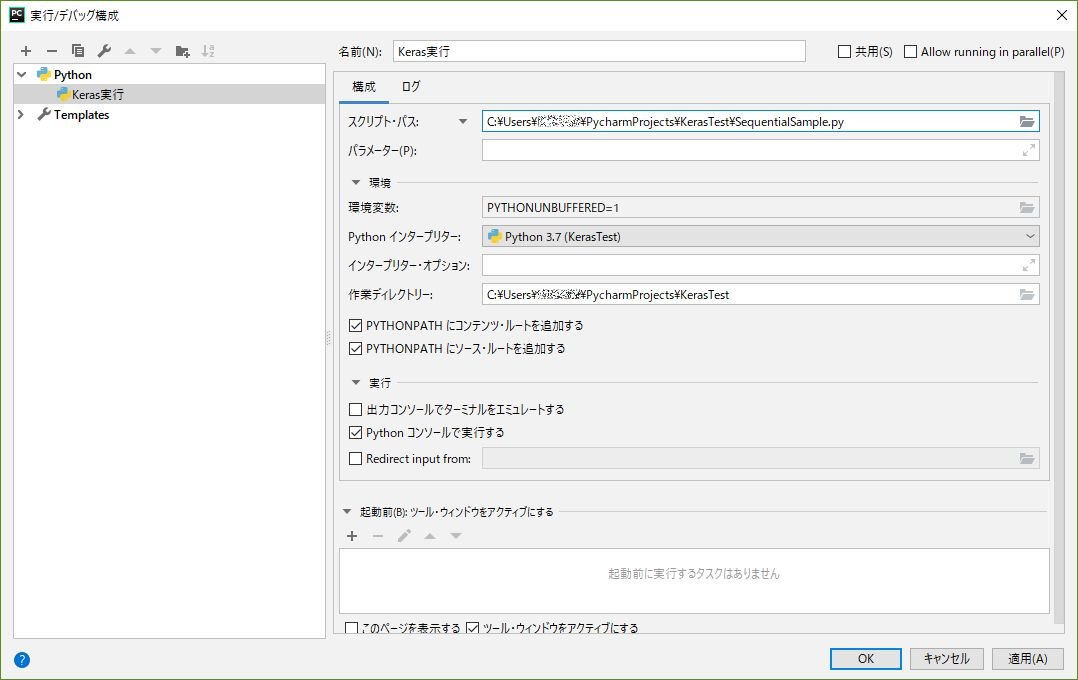
適用ボタンを押した後、OKボタンを押して実行/デバッグ構成画面を閉じます。
PyCharm右上に設定した「Keras実行」が表示され、横の緑三角ボタンが活性化します。
次回以降、緑三角ボタンを押すことで対象プログラムを実行することが出来ます。
![]()
緑三角ボタンを押して実行してみます。

以上でKerasのプログラム実行は終わりです。
ちなみに、コンソールい出力されているlossやaccは、ざっくり以下のような意味です。
- loss:学習データで学習を行った際の損失の値。0に近づく程、正しく学習できているということ。
- acc:学習データの精度の値。1に近づくほど、正しい結果が得られているということ。
Kerasに関する知識
Kerasを使用するにあたって、以下の用語および使い方等を理解しておく必要があります。
モデルの作成および追加
Sequentialモデルは層を積み重ねたものであり、コンストラクタにレイヤー(層)のインスタンスのリストを与えることで作成することが出来ます。
from keras.models import Sequential
from keras.layers import Dense, Activation
# Sequentialモデル作成(コンストラクタにインスタンスのリストを与える)
model = Sequential([
Dense(32, input_shape=(784,)),
Activation('relu'),
Dense(10),
Activation('softmax'),
])
また、add()メソッドを使ってレイヤー(層)を追加することが出来ます。
# モデルへのレイヤー追加
model = Sequential()
model.add(Dense(32, input_dim=784))
model.add(Activation('relu'))
Sequentialモデルは、最初のレイヤー(層)に入力のshapeを指定する必要があります。
入力のshapeを指定する方法はいくつかあり、以下の2つは等価の設定です。
# 1.input_shape model = Sequential() model.add(Dense(32, input_shape=(784,))) # 2.input_dim model = Sequential() model.add(Dense(32, input_dim=784))
コンパイル
compileメソッドを用いて、どのような学習処理を行なうかを設定します。
以下の3つの引数を指定します。
- 最適化アルゴリズム:optimizer=’rmsprop’など
- 損失関数:loss=’categorical_crossentropy’など
- 評価関数のリスト:metrics=[‘accuracy’]など。自分で定義することも可能
以下は設定例です。
# 例)マルチクラス分類問題の場合
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 例)平均二乗誤差を最小化する回帰問題の場合
model.compile(optimizer='rmsprop',
loss='mse')
# 独自定義の評価関数を定義
import keras.backend as K
def mean_pred(y_true, y_pred):
return K.mean(y_pred)
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy', mean_pred])
学習
モデルを学習させる場合、fit関数を使用します。
# 1つの入力から2クラス分類をするモデル
model = Sequential()
model.add(Dense(32, activation='relu', input_dim=100))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
# ダミーデータの作成
import numpy as np
data = np.random.random((1000, 100))
labels = np.random.randint(2, size=(1000, 1))
# 各イテレーションのバッチサイズを32で学習を行なう
model.fit(data, labels, epochs=10, batch_size=32)
上記の例では、fit関数の引数内容は以下の通りです。
data:学習データ
labels:ターゲットデータ
epochs:学習回数
batch_size:バッチサイズ(データをニューラルネットに1度に全て与えるわけではなく、幾つかのデータセットに分けて与えることになる。そのデータセットのサイズのこと。)
epocksやbatch_sizeについての参考
https://towardsdatascience.com/epoch-vs-iterations-vs-batch-size-4dfb9c7ce9c9
参考
Keras公式:SequentialモデルでKerasを始めてみよう
https://keras.io/ja/getting-started/sequential-model-guide/
Keras公式:GitHubのKerasサンプル
https://github.com/keras-team/keras/tree/master/examples
Keras公式:The Sequential model API
https://keras.io/models/sequential/
Keras公式:Keras FAQ: Kerasに関するよくある質問
https://keras.io/ja/getting-started/faq/