Kerasで学習を中断した後、途中から再開する方法
Kerasで学習を中断した後、途中から再開する方法をご紹介します。
- モデルを学習途中(エポック単位)で出力する。
- 出力したモデルを読み込み学習を再開する。
目次
条件
- Windows 10 64bit
- Python 3.7.0
- Keras 2.1.2
- tensorflow 1.14.1
- matplotlib 3.1.0
モデルの出力
モデルを訓練する際に、model.fit()の「callbacks=」に「ModelCheckpoint」を指定することで、適宜モデルを出力することが出来ます。
サンプルソース
以下はサンプルソースです。
ModelCheckpoint()でモデルの出力先パス等を指定し、model.fitの「callbacks=」で渡します。
from __future__ import division, print_function
from keras.callbacks import ModelCheckpoint
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.utils import np_utils
import os
import matplotlib.pyplot as plt
BATCH_SIZE = 128
NUM_EPOCHS = 20
MODEL_DIR = "/tmp"
(Xtrain, ytrain), (Xtest, ytest) = mnist.load_data()
Xtrain = Xtrain.reshape(60000, 784).astype("float32") / 255
Xtest = Xtest.reshape(10000, 784).astype("float32") / 255
Ytrain = np_utils.to_categorical(ytrain, 10)
Ytest = np_utils.to_categorical(ytest, 10)
print(Xtrain.shape, Xtest.shape, Ytrain.shape, Ytest.shape)
# モデル定義
model = Sequential()
model.add(Dense(512, input_shape=(784,), activation="relu"))
model.add(Dropout(0.2))
model.add(Dense(512, activation="relu"))
model.add(Dropout(0.2))
model.add(Dense(10, activation="softmax"))
model.summary()
model.compile(optimizer="rmsprop", loss="categorical_crossentropy",
metrics=["accuracy"])
if not os.path.exists(MODEL_DIR): # ディレクトリが存在しない場合、作成する。
os.makedirs(MODEL_DIR)
checkpoint = ModelCheckpoint(
filepath=os.path.join(MODEL_DIR, "model-{epoch:02d}.h5"), save_best_only=True) # 精度が向上した場合のみ保存する。
# 学習実行
history = model.fit(Xtrain, Ytrain, batch_size=BATCH_SIZE, nb_epoch=NUM_EPOCHS,
validation_split=0.1, callbacks=[checkpoint])
# グラフ描画
# Accuracy
plt.plot(range(1, NUM_EPOCHS+1), history.history['acc'], "o-")
plt.plot(range(1, NUM_EPOCHS+1), history.history['val_acc'], "o-")
plt.title('model accuracy')
plt.ylabel('accuracy') # Y軸ラベル
plt.xlabel('epoch') # X軸ラベル
plt.legend(['train', 'test'], loc='upper left')
plt.show()
# loss
plt.plot(range(1, NUM_EPOCHS+1), history.history['loss'], "o-")
plt.plot(range(1, NUM_EPOCHS+1), history.history['val_loss'], "o-")
plt.title('model loss')
plt.ylabel('loss') # Y軸ラベル
plt.xlabel('epoch') # X軸ラベル
plt.legend(['train', 'test'], loc='upper right')
plt.show()
実行結果
ModelCheckpoint()で「save_best_only=True」としているため、精度が向上した場合のみモデルが保存されます。
今回は、エポック1,3,6でモデルが保存されました。

損失関数のグラフで確認すると以下のことが分かります。
- testに対する損失の最小値が更新されているのは、epoch:1,3,6。
- epoch:7以降は、testに対する損失は増加傾向にある。(過学習)

毎回出力
ModelCheckpoint()で「save_best_only=False」とすれば、epochごとにモデルを出力することが出来ます。
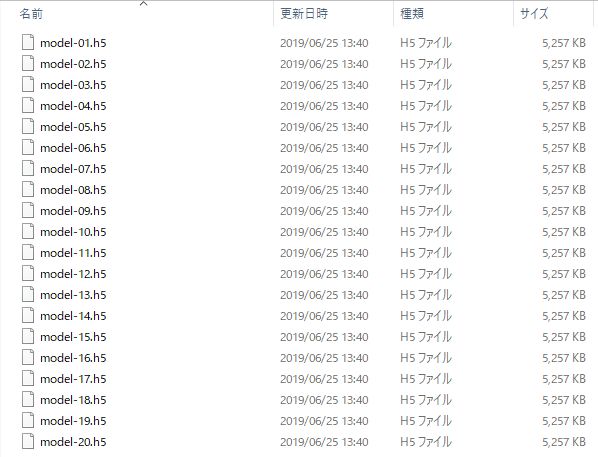
途中から学習実行
サンプルソース
以下のようにモデルをロードします。
- model.load_weights(os.path.join(MODEL_DIR, “model-07.h5”))
今回は、epoch:7のモデルを読み込んで、その後さらに20回学習を行います。
from __future__ import division, print_function
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.utils import np_utils
import os
import matplotlib.pyplot as plt
BATCH_SIZE = 128
NUM_EPOCHS = 20
MODEL_DIR = "/tmp"
(Xtrain, ytrain), (Xtest, ytest) = mnist.load_data()
Xtrain = Xtrain.reshape(60000, 784).astype("float32") / 255
Xtest = Xtest.reshape(10000, 784).astype("float32") / 255
Ytrain = np_utils.to_categorical(ytrain, 10)
Ytest = np_utils.to_categorical(ytest, 10)
print(Xtrain.shape, Xtest.shape, Ytrain.shape, Ytest.shape)
# モデル定義
model = Sequential()
model.add(Dense(512, input_shape=(784,), activation="relu"))
model.add(Dropout(0.2))
model.add(Dense(512, activation="relu"))
model.add(Dropout(0.2))
model.add(Dense(10, activation="softmax"))
model.summary()
model.compile(optimizer="rmsprop", loss="categorical_crossentropy",
metrics=["accuracy"])
# モデルの読み込み
model.load_weights(os.path.join(MODEL_DIR, "model-07.h5")) # epoch:7のモデルを指定
# 学習実行
history = model.fit(Xtrain, Ytrain, batch_size=BATCH_SIZE, nb_epoch=NUM_EPOCHS,
validation_split=0.1)
# グラフ描画
# Accuracy
plt.plot(range(1, NUM_EPOCHS+1), history.history['acc'], "o-")
plt.plot(range(1, NUM_EPOCHS+1), history.history['val_acc'], "o-")
plt.title('model accuracy')
plt.ylabel('accuracy') # Y軸ラベル
plt.xlabel('epoch') # X軸ラベル
plt.legend(['train', 'test'], loc='upper left')
plt.show()
# loss
plt.plot(range(1, NUM_EPOCHS+1), history.history['loss'], "o-")
plt.plot(range(1, NUM_EPOCHS+1), history.history['val_loss'], "o-")
plt.title('model loss')
plt.ylabel('loss') # Y軸ラベル
plt.xlabel('epoch') # X軸ラベル
plt.legend(['train', 'test'], loc='upper right')
plt.show()
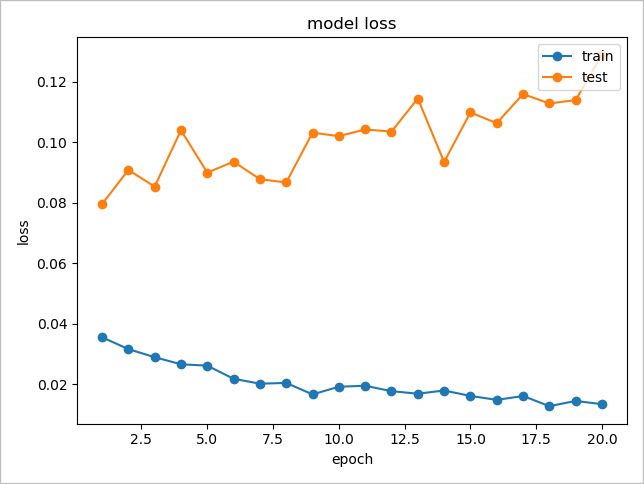
実行結果
以下のグラフから、初めから学習した場合と比較して、損失が少ない値から開始されていることが分かります。
epoch:7のモデルを読み込んで20回学習
初めから学習した場合

以上のように、モデルを出力したりロードしたりすることで途中から学習を再開することが出来ます。
参考
Keras Documentation:コールバックの使い方
https://keras.io/ja/callbacks/
Keras Documentation:モデルについて
https://keras.io/ja/models/about-keras-models/
Qiita:最良のモデルを保存する(ModelCheckpointの使い方)
https://qiita.com/tom_eng_ltd/items/7ae0814c2d133431c84a


Google Colabの接続が切れて、計算結果が消えてしまう問題があったとき、この記事が大変参考になりました。どうもありがとうございました。