Pythonでスクレイピング
Pythonでスクレイピングする方法をご紹介します。
目次
条件
- Python 3.7.0
- requests
- HTMLParser
スクレイピングとは?
ウェブスクレイピング(英: Web scraping)とは、ウェブサイトから情報を抽出するコンピュータソフトウェア技術のこと。
出典:Wikipedia
ここでは例として、Pythonを用いてWebサイトから株価情報を抽出してみたいと思います。
Pythonでスクレイピング
「Yahooファイナンス」から株価情報を抽出します。
抽出するサイトのチェック
今回のターゲット銘柄は「GMOインターネット」です。
https://stocks.finance.yahoo.co.jp/stocks/history/?code=9449.T
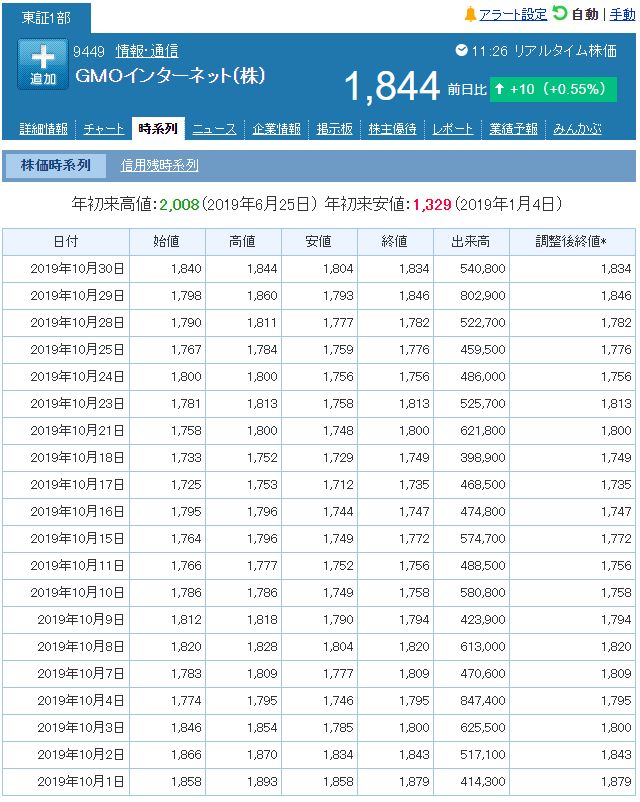
当該サイトを開いた状態で、右クリック > ページのソースを表示 でソースを表示します。
抽出したい対象のソースを抜粋すると、以下のような感じです。
<!--時系列--> <div class="padT12 marB10 clearFix"> <table width="100%" border="0" cellspacing="0" cellpadding="0" class="boardFin yjSt marB6"> <tr> <th width="20%">日付</th> <th width="12%">始値</th> <th width="12%">高値</th> <th width="12%">安値</th> <th width="12%">終値</th> <th width="12%">出来高</th> <th width="20%">調整後終値*</th> </tr><tr><td>2019年10月30日</td> <td>1,840</td> <td>1,844</td> <td>1,804</td> <td>1,834</td> <td>540,800</td> <td>1,834</td> </tr><tr><td>2019年10月29日</td> <td>1,798</td> <td>1,860</td> <td>1,793</td> <td>1,846</td> <td>802,900</td> <td>1,846</td> </tr><tr><td>2019年10月28日</td> <td>1,790</td> <td>1,811</td> <td>1,777</td> <td>1,782</td> <td>522,700</td> <td>1,782</td> </tr><tr><td>2019年10月25日</td> <td>1,767</td> <td>1,784</td> <td>1,759</td> <td>1,776</td> <td>459,500</td> <td>1,776</td> </tr><tr><td>2019年10月24日</td> <td>1,800</td> <td>1,800</td> <td>1,756</td> <td>1,756</td> <td>486,000</td> <td>1,756</td> </tr><tr><td>2019年10月23日</td> <td>1,781</td> <td>1,813</td> <td>1,758</td> <td>1,813</td> <td>525,700</td> <td>1,813</td> </tr><tr><td>2019年10月21日</td> <td>1,758</td> <td>1,800</td> <td>1,748</td> <td>1,800</td> <td>621,800</td> <td>1,800</td> </tr><tr><td>2019年10月18日</td> <td>1,733</td> <td>1,752</td> <td>1,729</td> <td>1,749</td> <td>398,900</td> <td>1,749</td> </tr><tr><td>2019年10月17日</td> <td>1,725</td> <td>1,753</td> <td>1,712</td> <td>1,735</td> <td>468,500</td> <td>1,735</td> </tr><tr><td>2019年10月16日</td> <td>1,795</td> <td>1,796</td> <td>1,744</td> <td>1,747</td> <td>474,800</td> <td>1,747</td> </tr><tr><td>2019年10月15日</td> <td>1,764</td> <td>1,796</td> <td>1,749</td> <td>1,772</td> <td>574,700</td> <td>1,772</td> </tr><tr><td>2019年10月11日</td> <td>1,766</td> <td>1,777</td> <td>1,752</td> <td>1,756</td> <td>488,500</td> <td>1,756</td> </tr><tr><td>2019年10月10日</td> <td>1,786</td> <td>1,786</td> <td>1,749</td> <td>1,758</td> <td>580,800</td> <td>1,758</td> </tr><tr><td>2019年10月9日</td> <td>1,812</td> <td>1,818</td> <td>1,790</td> <td>1,794</td> <td>423,900</td> <td>1,794</td> </tr><tr><td>2019年10月8日</td> <td>1,820</td> <td>1,828</td> <td>1,804</td> <td>1,820</td> <td>613,000</td> <td>1,820</td> </tr><tr><td>2019年10月7日</td> <td>1,783</td> <td>1,809</td> <td>1,777</td> <td>1,809</td> <td>470,600</td> <td>1,809</td> </tr><tr><td>2019年10月4日</td> <td>1,774</td> <td>1,795</td> <td>1,746</td> <td>1,795</td> <td>847,400</td> <td>1,795</td> </tr><tr><td>2019年10月3日</td> <td>1,846</td> <td>1,854</td> <td>1,785</td> <td>1,800</td> <td>625,500</td> <td>1,800</td> </tr><tr><td>2019年10月2日</td> <td>1,866</td> <td>1,870</td> <td>1,834</td> <td>1,843</td> <td>517,100</td> <td>1,843</td> </tr><tr><td>2019年10月1日</td> <td>1,858</td> <td>1,893</td> <td>1,858</td> <td>1,879</td> <td>414,300</td> <td>1,879</td> </tr></table> <div class="stocksCsv">
Pythonによるデータ抽出
Pythonでスクレイピングを実施するためのライブラリは複数存在します。
ここでは有名なHTTPライブラリである「requests」を使用します。
また、HTMLを解析するために「HTMLParser」を用います。
以下のコマンドでインストールします。
$ pip install requests
以下はサンプルソースです。
株価一覧テーブルから、「日付」「始値」「高値」「安値」「終値」「出来高」を抽出して表示します。
import requests
from html.parser import HTMLParser
URL = 'https://stocks.finance.yahoo.co.jp/stocks/history/?code=9449.T'
class MyHTMLParser(HTMLParser):
def __init__(self):
HTMLParser.__init__(self)
self.table = False # ターゲットのtableタグかどうか
self.tr = False # ターゲットのtrタグかどうか
self.td = False # ターゲットのtdタグかどうか
self.tr_count = 0 # trタグのカウント
self.td_count = 0 # tdタグのカウント
def handle_starttag(self, tag, attrs):
attrs = dict(attrs)
# ターゲットのテーブルの場合
if tag == "table" and "class" in attrs and attrs['class'] == "boardFin yjSt marB6":
self.table = True # ターゲットのtableタグ
elif self.table and tag == "tr":
if self.tr_count == 0: # 1つ目のtrタグの場合
self.tr_count += 1;
else:
self.tr = True # ターゲットのtrタグ
elif self.table and self.tr and tag == "td":
self.td = True # ターゲットのtrタグ
self.td_count += 1 # カウントをインクリメント
def handle_endtag(self, tag):
if self.table and tag == "table": # tableタグが終わるとき
self.table = False
self.tr = False
elif self.table and tag == "tr": # trタグが終わるとき
self.td_count = 0 # カウントをリセット
elif self.table and self.tr and tag == "td": # tdタグが終わるとき
self.td = False
def handle_data(self, data):
if self.td:
if self.td_count == 1:
print("日付:" + data)
elif self.td_count == 2:
print("始値:" + data)
elif self.td_count == 3:
print("高値:" + data)
elif self.td_count == 4:
print("安値:" + data)
elif self.td_count == 5:
print("終値:" + data)
elif self.td_count == 6:
print("出来高:" + data)
def error(self, message):
pass
def main():
r = requests.get(URL)
parser = MyHTMLParser()
parser.feed(r.text)
if __name__ == '__main__':
main()
実行結果
想定通りのデータが抽出出来ていることがわかります。
日付:2019年10月30日 始値:1,840 高値:1,844 安値:1,804 終値:1,834 出来高:540,800 日付:2019年10月29日 始値:1,798 高値:1,860 安値:1,793 終値:1,846 出来高:802,900 日付:2019年10月28日 始値:1,790 高値:1,811 安値:1,777 終値:1,782 出来高:522,700 日付:2019年10月25日 始値:1,767 高値:1,784 安値:1,759 終値:1,776 出来高:459,500 日付:2019年10月24日 始値:1,800 高値:1,800 安値:1,756 終値:1,756 出来高:486,000 日付:2019年10月23日 始値:1,781 高値:1,813 安値:1,758 終値:1,813 出来高:525,700 日付:2019年10月21日 始値:1,758 高値:1,800 安値:1,748 終値:1,800 出来高:621,800 日付:2019年10月18日 始値:1,733 高値:1,752 安値:1,729 終値:1,749 出来高:398,900 日付:2019年10月17日 始値:1,725 高値:1,753 安値:1,712 終値:1,735 出来高:468,500 日付:2019年10月16日 始値:1,795 高値:1,796 安値:1,744 終値:1,747 出来高:474,800 日付:2019年10月15日 始値:1,764 高値:1,796 安値:1,749 終値:1,772 出来高:574,700 日付:2019年10月11日 始値:1,766 高値:1,777 安値:1,752 終値:1,756 出来高:488,500 日付:2019年10月10日 始値:1,786 高値:1,786 安値:1,749 終値:1,758 出来高:580,800 日付:2019年10月9日 始値:1,812 高値:1,818 安値:1,790 終値:1,794 出来高:423,900 日付:2019年10月8日 始値:1,820 高値:1,828 安値:1,804 終値:1,820 出来高:613,000 日付:2019年10月7日 始値:1,783 高値:1,809 安値:1,777 終値:1,809 出来高:470,600 日付:2019年10月4日 始値:1,774 高値:1,795 安値:1,746 終値:1,795 出来高:847,400 日付:2019年10月3日 始値:1,846 高値:1,854 安値:1,785 終値:1,800 出来高:625,500 日付:2019年10月2日 始値:1,866 高値:1,870 安値:1,834 終値:1,843 出来高:517,100 日付:2019年10月1日 始値:1,858 高値:1,893 安値:1,858 終値:1,879 出来高:414,300
解説
サンプルソースの大まかな解説です。
requestsで取得したHTMLデータをMyHTMLParser()でパースします。
MyHTMLParser()では以下のような処理を行っています。
- コンストラクタ(__init__):各変数の初期化。
- 開始タグを扱う処理(handle_starttag)
- ターゲットのtableタグであった場合、フラグを立てる。(self.table = True)
- ターゲットのtableタグかつtrタグの場合、2つ目以降のtrであればフラグを立てる。(self.tr = True)
- ターゲットのtableタグかつtrタグかつtdタグの場合、フラグを立てる。(self.td = True)また、tdカウントをインクリメントする。
- 終了タグを扱う処理(handle_endtag)
- ターゲットのtableタグの場合、フラグを初期化する。
- ターゲットのtableタグかつtrタグの場合、tdのカウントを初期化する。
- ターゲットのtableタグかつtrタグかつtdタグの場合、フラグを初期化する。
- データを扱う処理(handle_data)
- ターゲットのtdタグの場合、tdカウントに応じた出力を行う。(日付、始値、高値、安値、終値、出来高)
参考
Wikipedia:ウェブスクレイピング
Yahoo ファイナンス
Requests: 人間のためのHTTP
https://requests-docs-ja.readthedocs.io/en/latest/
html.parser— HTML および XHTML のシンプルなパーサー
https://docs.python.org/ja/3/library/html.parser.html
Qiita:図解 HTMLParser
https://qiita.com/rtok/items/7ae9be2ae531bb21614f

